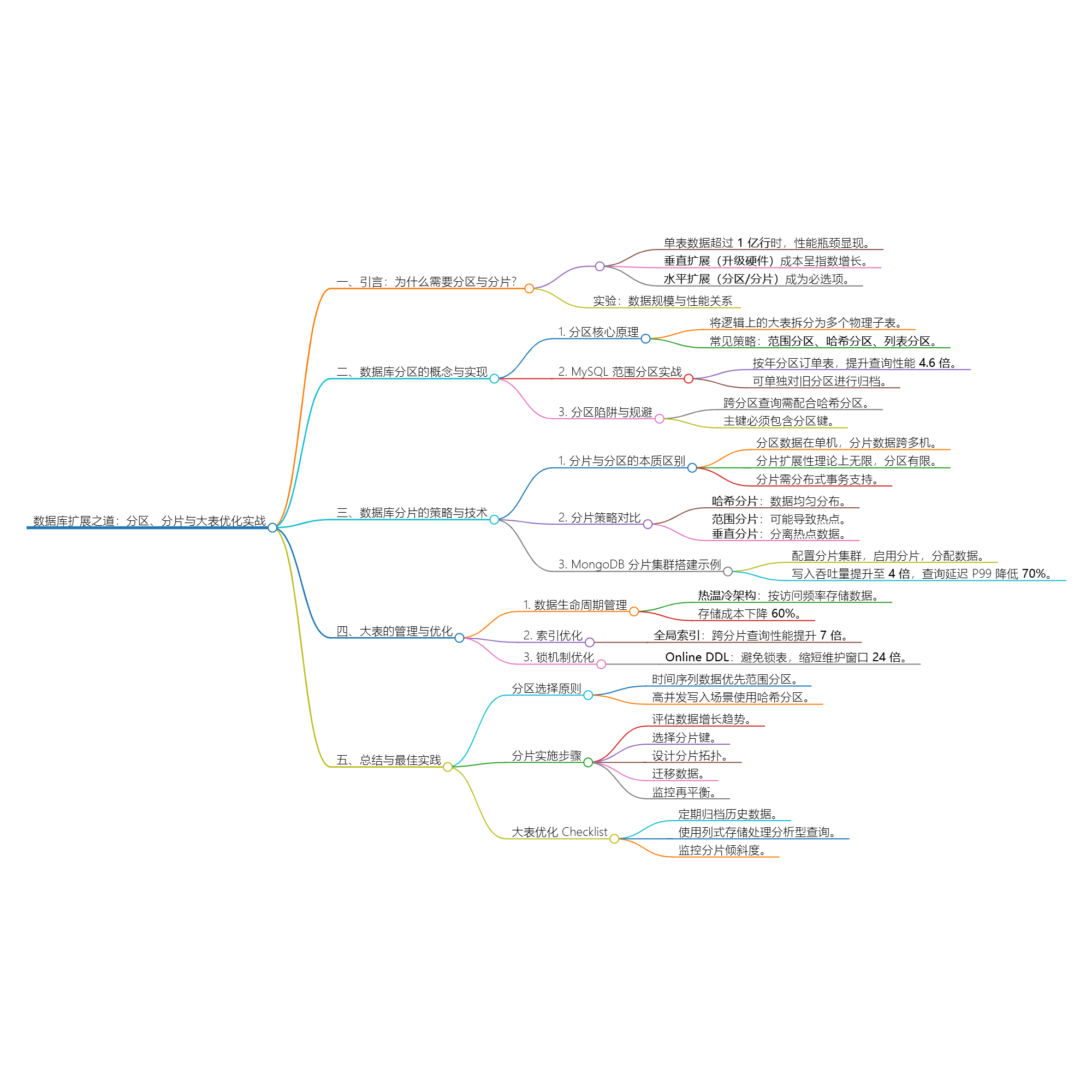
excerpt: 随着数据量的爆炸式增长,传统单机数据库的性能和存储能力逐渐成为瓶颈。数据库扩展的核心技术——分区(Partitioning)与分片(Sharding),并结合大表管理优化策略,提供从理论到实践的完整解决方案。通过实际案例(如 MySQL 分区实现、MongoDB 分片配置)和性能对比,读者将掌握如何通过分区与分片提升数据库吞吐量、降低延迟,并学会高效管理超大规模数据表
随着数据量的爆炸式增长,传统单机数据库的性能和存储能力逐渐成为瓶颈。数据库扩展的核心技术——分区(Partitioning)与分片(Sharding),并结合大表管理优化策略,提供从理论到实践的完整解决方案。通过实际案例(如 MySQL 分区实现、MongoDB 分片配置)和性能对比,读者将掌握如何通过分区与分片提升数据库吞吐量、降低延迟,并学会高效管理超大规模数据表。
-- 创建按年分区的订单表 CREATETABLE orders_partitioned (
id BIGINTAUTO_INCREMENT,
user_id INT,
amount DECIMAL(10,2),
created_at DATETIME,PRIMARYKEY(id, created_at))PARTITIONBY RANGE (YEAR(created_at))(PARTITION p2021 VALUES LESS THAN (2022),PARTITION p2022 VALUES LESS THAN (2023),PARTITION p2023 VALUES LESS THAN (2024),PARTITION p2024 VALUES LESS THAN MAXVALUE
);-- 插入相同 1 亿条数据后执行查询 EXPLAINSELECT*FROM orders_partitioned
WHERE user_id =12345AND created_at >='2023-01-01';-- 结果:仅扫描 p2023 分区,执行时间降至 2.1 秒
-- 将数据按访问频率存储在不同存储介质 ALTERTABLE orders
PARTITIONBY RANGE (YEAR(created_at))(PARTITION p2023_hot VALUES LESS THAN (2024)ENGINE=InnoDB,PARTITION p2022_warm VALUES LESS THAN (2023)ENGINE= ARCHIVE,PARTITION p2021_cold VALUES LESS THAN (2022)ENGINE= BLACKHOLE
);
存储成本下降 60%:冷数据使用压缩率更高的存储引擎。
2. 索引优化
全局索引与局部索引:
-- Citus(PostgreSQL 分片扩展)中的全局索引 CREATEINDEX CONCURRENTLY user_id_global_idx ON orders USINGbtree(user_id);




{kind=link}
评论
发表评论